In my previous post I already explained what I understand by the term DevOps: it is a way of improving the software delivery process by bringing together devs, ops, and a lot of other teams with the purpose of delivering changes fast while keeping a reliable environment.
I also gave a summary of how I used this DevOps mindset as a guide to solve one of the most urgent and visible problems that existed within the realm of software delivery in one of a large traditional enterprise I worked for in the past (and is very typical for similar enterprises): the manual nature of the configuration and release management activities and the increasing challenges that it brought to the efficient delivery of software. The solution was to rationalize the software delivery process and to implement configuration and release management tools to support the release management team.
But the manual nature of configuration and release management was not the only problem that stood in the way of an efficient software delivery process and not all of these problems were magically solved by this one solution either.
Before taking a closer look at the exact problems I’m talking about, let me first draw out the playing field by explaining how the different teams in the IT department were organized, what their roles and responsibilities were and how they interacted with one another.
This introduction should help in getting a better appreciation of the problems and will be a good starting point when we want to apply some root cause analysis of the found problems. This is important because it may well be that the visible problem is only a consequence of a deeper lying invisible (or less-visible) problem. Most of the time it will not help to solve this visible problem, as the root problem will just find another way to manifest itself. And if we’re lucky, by solving the root problem some other visible problems that exist down the wire may get automatically solved in the same go. So it’s always interesting to try to find the relationships between the various problems before jumping into solution-mode.
 Side note: If we continue to dig into the root cause analysis we should eventually end up on the level where the fundamental, strategic decisions are made on running the whole IT department or even the whole business. On this level, making changes towards a better software delivery process may have huge consequences on other parts of the business so we should always be cautious for possible negative side-effects.
Side note: If we continue to dig into the root cause analysis we should eventually end up on the level where the fundamental, strategic decisions are made on running the whole IT department or even the whole business. On this level, making changes towards a better software delivery process may have huge consequences on other parts of the business so we should always be cautious for possible negative side-effects.
OK here I go with an overview of the teams involved in the software delivery process:
Teams
 The Strategy and Architecture teams
The Strategy and Architecture teams
As with so many other enterprises of which information technology is not the core business, the general rule on automating new business processes was “buy before build”: first look on the market if any business applications already exist that can do the job and only if nothing is found evaluate the possibility to build one in-house.
As we will see, this short and simple rule has a big impact on the whole structure and organization of the IT department.
The first impact is on the heterogeneity of the environment: although there were some constraints these third party applications had to take into account before being considered – I’m thinking about the support for specific database vendors, application servers and integration technologies – it is the vendor who basically decides the (remaining) technology stack of the application, the internal design, the used libraries, the type of installation (manual or automated), the (lack of) testability, etc. With so many third party applications that together form the corporate application landscape the result is a very heterogeneous environment.
Secondly a strong focus on the integration of these applications is needed in order to deliver a consistent service to the business side. The applications have their own specialized view of the world but at the same time must act as producers and consumers of each others data.This means that, in addition to simply transferring the data, at some point also a transformation of this data must be done from one world to the other to make them understand each other.
The implementation of these integrations was done with specialized development platforms. The data was initially transferred during nightly ETL batches but due to the need for more up-to-date information EAI and messaging was gradually replacing these batches.
With the growth of the application landscape over time and as it became more and more difficult to keep track of the different data flows and of the ownership of the data (who is responsible for which data) a strategic decision had been made long ago to create a single system of record, a central data hub in other words, to provide a one-and-only “Source of Truth”. Applications that create data (or get them from the outside world) have to feed it into the data hub and applications that need data have to get it from the data hub. Architecturally this is definitely a sound decision that can simplify life a lot but software delivery wise it creates an interesting situation: each change that involves modifying the data flows from producer to consumer (which most of the changes do) automatically creates a dependency on the data hub’s development team, thereby coupling the otherwise unrelated changes, if not through their associated software components then at least on the project management level of the data hub’s development team.
Another strategic decision was the mutualisation of infrastructure: all in-house developed software that shared the same development technology had to be hosted on one shared server. Sharing of infrastructure gives the best overall capacity (valleys in one app cover up for peaks in another app). It also keeps the total number of servers low which rationalizes on the maintenance efforts by the ops teams. And new projects are quickly up-to-speed because there is no need to buy and setup the infrastructure. But here as well, a coupling is created between the otherwise unrelated software components. If one misbehaves the others are impacted.
Higher management generally preferred stability and compliance over agility and reduction of feedback cycle. They were inspired by corporate process frameworks like CMMi, ITIL and TOGAF. Unfortunately for some bizarre reason these frameworks always seem to get implemented in a more bureaucratic, top-to-bottom feedback-loop-allergic way than what I would consider ideal. On the other hand, there was less awareness of the latest evolutions that are happening on the work floor like agile development, the DevOps movement, open source tooling for automated testing, provisioning and monitoring, etc. All concepts that tend to have a more bottom-up direction.
The Development Tools team
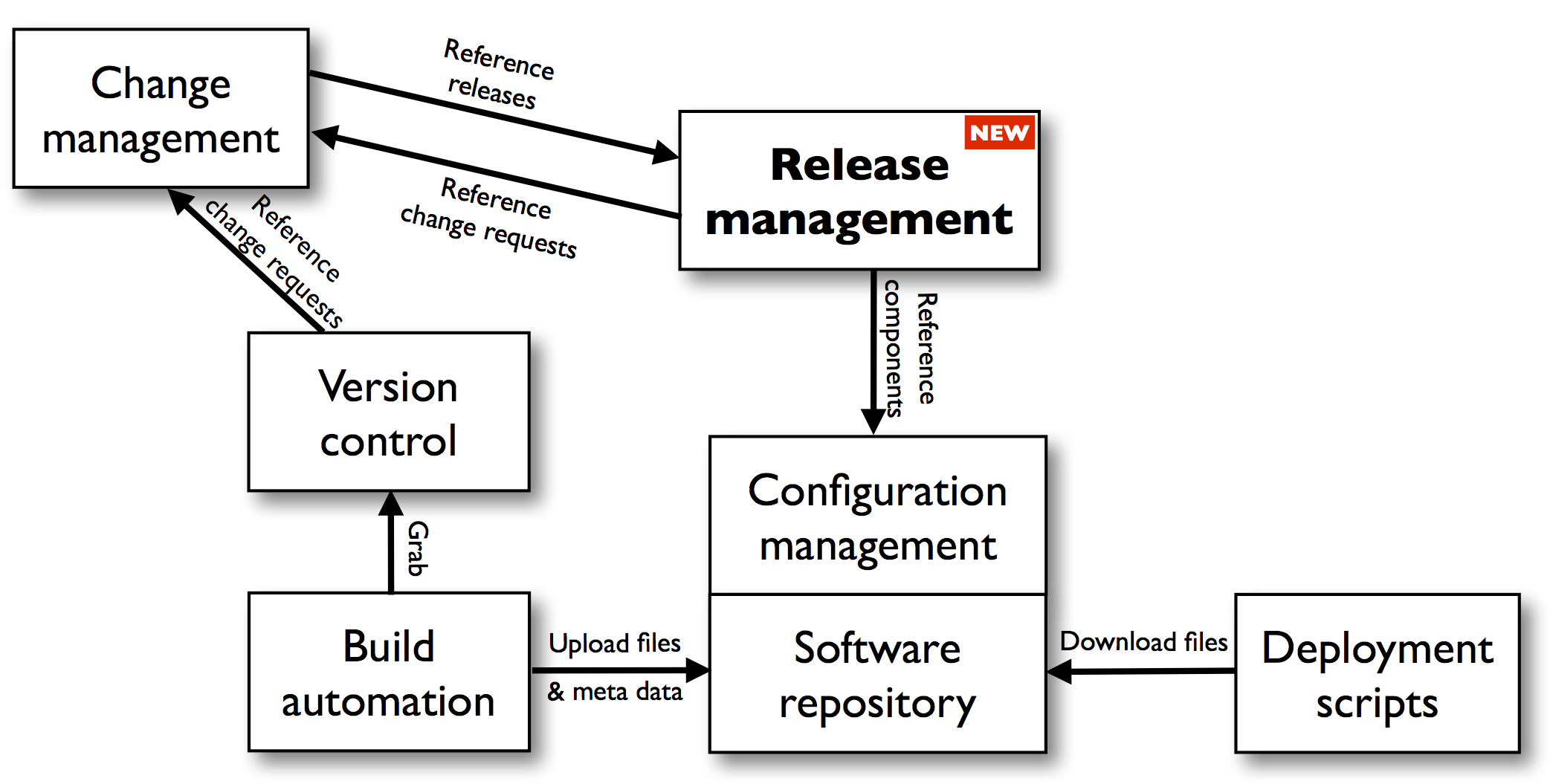
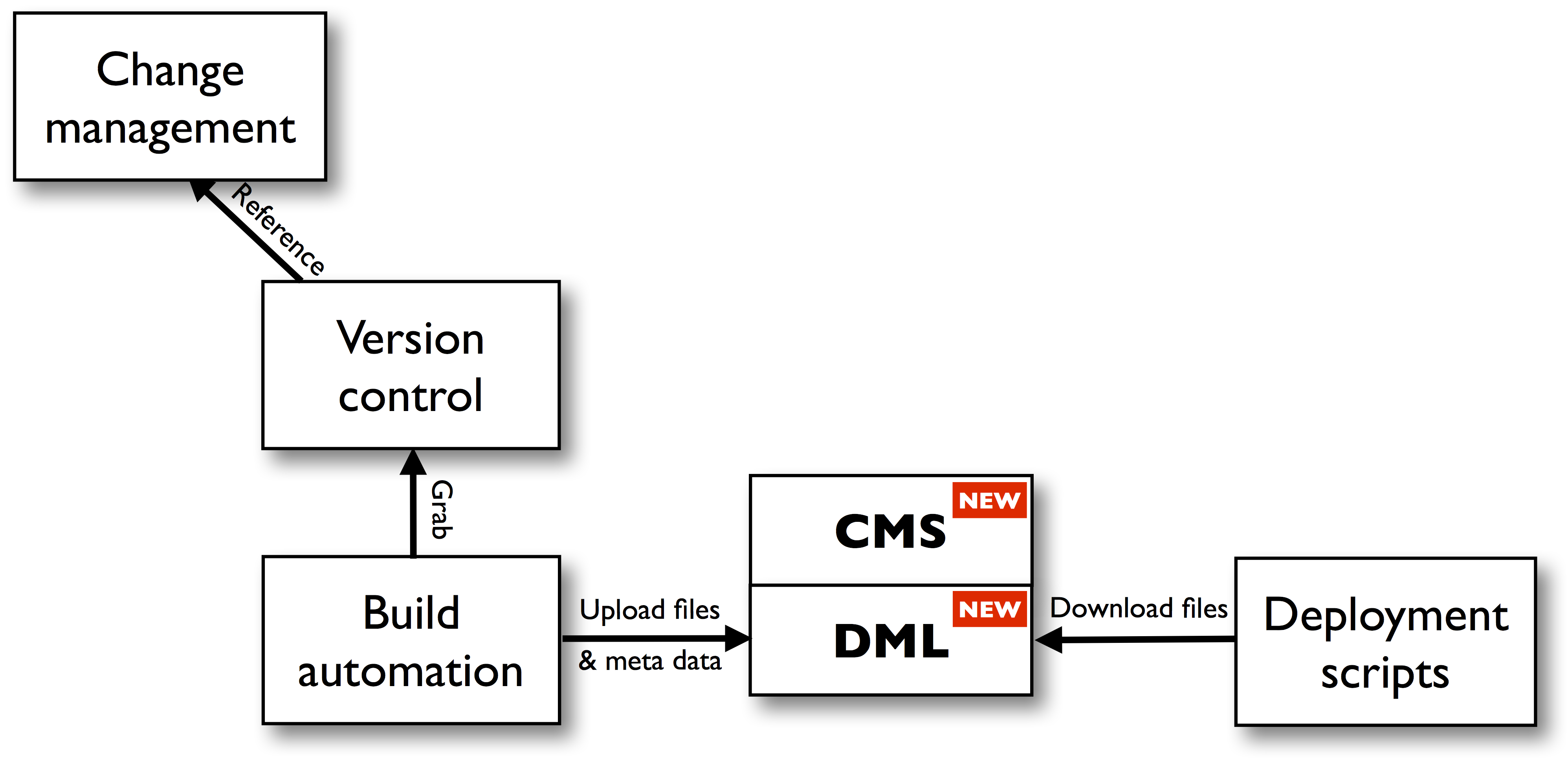
The Development Tools team was responsible for defining the standards and guidelines for the supported development technologies and for the implementation of all cross-functional needs of the development teams: the development tools, the version control systems, the build and deployment automations, framework components, etc.
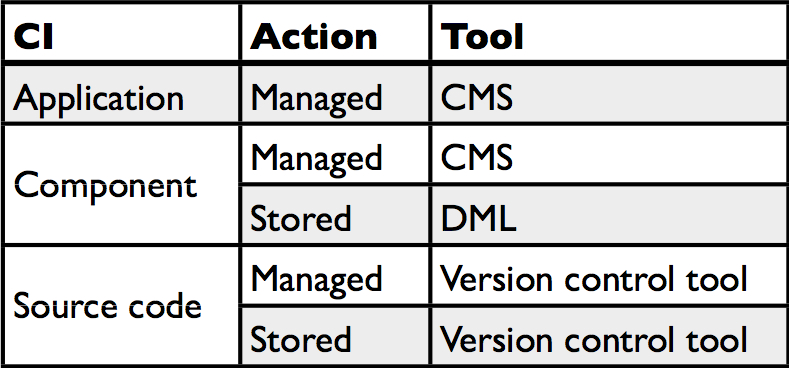
Unfortunately, for the levels of configuration management that go beyond what version control systems have to offer there was no tooling or automation in place. It was up to the development teams to keep track of which software component was part of which application and which version of which component was deployed in which environment. Most of the time this was done in Excel by the person that last joined the team ;-). There was also no uniform place to store the different versions of the components. Each build tool had its own dedicated software repository and non-buildable artifacts like database scripts were even manually stored on whatever location was accessible by the ops team that was responsible for its deployment.
Code reviews, although part of this team’s objectives, were done very infrequently due to a lack of time (in practice they only happened a posteriori, after something bad had already occurred). As a consequence the standards and guidelines were not always followed. The team also had a limited involvement in the hiring process of new developers. Both these shortcomings acted as catalysts to the increase of heterogeneity of both the development teams as the code base.
The Development teams
There were about 15 development teams, each one covering the IT needs for one business domain. As I already mentioned before most of these teams focused primarily on the integration of the third party applications. Only a few of them worked on completely in-house built applications.
The developer profiles were quite diverse: there were the gurus as well as the relatively novices, the passionate “eat-sleep-dream-coders” as well as the “9-to-5” types, the academics as well as the cowboys pragmatics, the “cutting-edge” types as well as the “traditional” types. Orthogonally you also had the job-hopping, the different cultures and languages etc. to make it quite a diverse community. But despite all these apparent differences, each team was relatively successful in finding their way to cooperate and deliver value.
The unfortunate side effect of this was that the internal processes and habits within each team work varied considerably, a fact that also surfaced in their varying needs towards configuration management and release management: some wanted it as simple as possible, others wanted to tweak it to the extreme in order to facilitate their exotic requirements.
But next to these differences, there were also quite some – unfortunate – similarities in problem areas between the teams. Lack of logging and unit testing was widespread. So was their struggle to keep track of all the files and instructions that had to be included in the next release. Development and delivery in small increments was only done by a small number of teams, dark releases or feature flags were not done by any team.
The development teams responsible for the core application had a rotating 24/7 on-call system to make sure that someone was available to help out the ops guys whenever an emergency occurred. During the weekend releases a senior member of each development team would be on-site to help solve potential deployment issues to keep the release as efficiently as possible.
The Change Management team
The change management process was inspired by ITIL and combined with the CMMi-based software development life cycle into an automated workflow. A whole range of statuses and transitions existed between the creation and the final delivery of the change request.
The change manager’s role was to review and either approve or reject each change request when it was assigned to a release (releases were company-wide and happened monthly, see more in the next section) and before it was deployed to the UAT and production environments. The approvals depended on formality checks (is everything filled in correctly, are the changes signed-off by the testers, did they register their test runs, …) and ops availability and to a much lesser degree on content and business risk assessment.
All of this together made the creation and follow-up of change request quite a formal and time consuming experience. As a consequence, most of the time during the life cycle of the change there was a disconnect between the reality and what the tool showed because people forgot to update it.
The Release Management team – release planning
The corporate release strategy as decided by the release management team was to have company-wide (a.k.a. orchestrated) monthly releases with cold deployments to production during the weekend. A release is scheduled as a set of phases with milestones in between: development and integration, UAT testing, production. Changes that for some reason didn’t fit in this release schedule could request an on-demand application-specific release. Same for bug fixes.
There was a static set of environments that were shared between all applications. The “early” environments allowed the development teams to deploy their software whenever they needed to while for the “later” environments the release management team acted as the gatekeeper, with the gates only opening during the predefined deployment windows as foreseen in the release schedules.
It was very difficult (and expensive) to set up new environments due to the high cost of manually setting it up, the cost of keeping it all operational, licensing costs, high storage needs for databases (see further: testing on a copy of production data). It was also very hard to exactly duplicate existing servers because there was no reliable way of tracking all previous manipulations on the already existing servers. As a consequence, the test teams had to share the existing environments which was regularly a source of interference, especially if major changes to the application landscape – that typically span more than one release cycle – had to be tested in parallel with the regular changes.
The Release Management team – release coordination
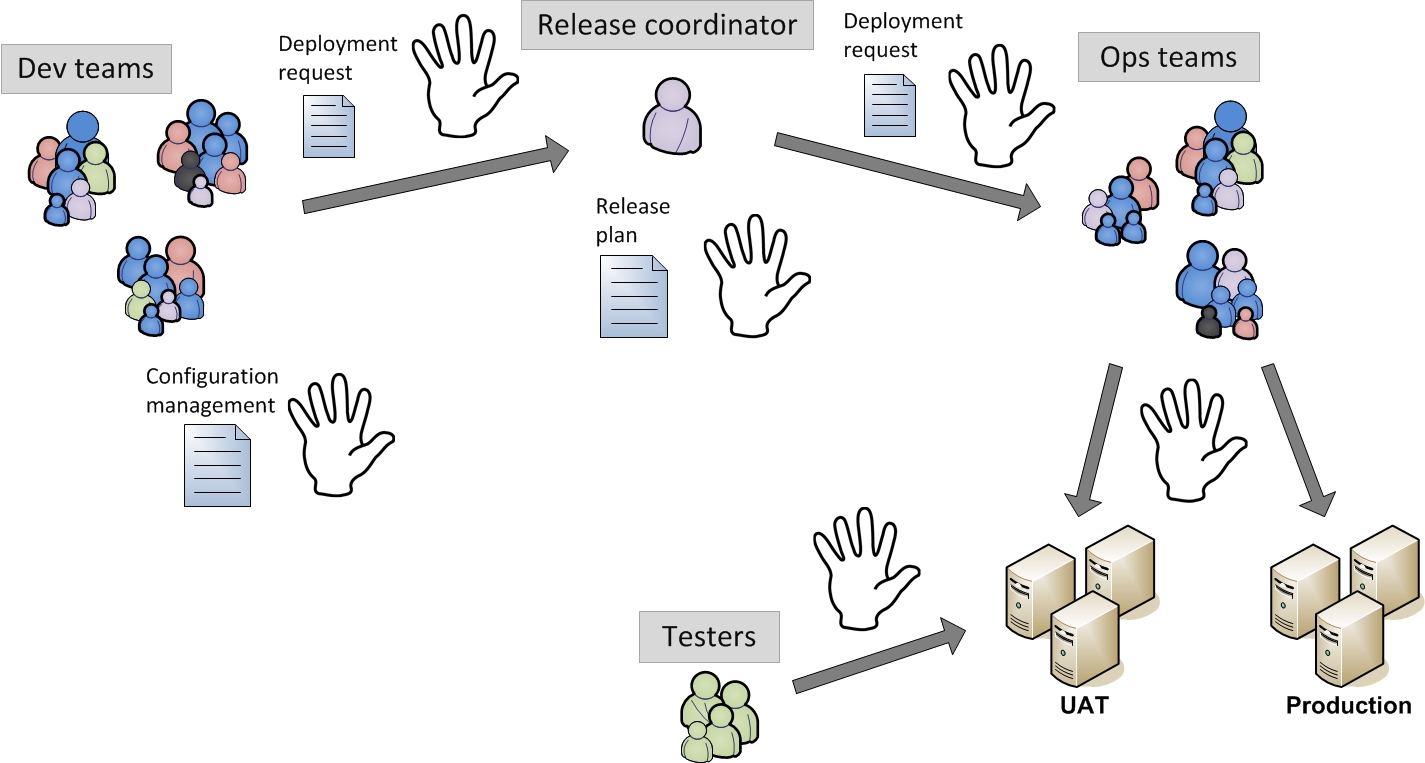
The release coordinator received the deployment requests from the developers and assembled them into a release plan. Although the release coordinator was supposed to validate the deployment instructions before accepting them in the release plan, in practice only a quick formality check was done due to a lack of time.
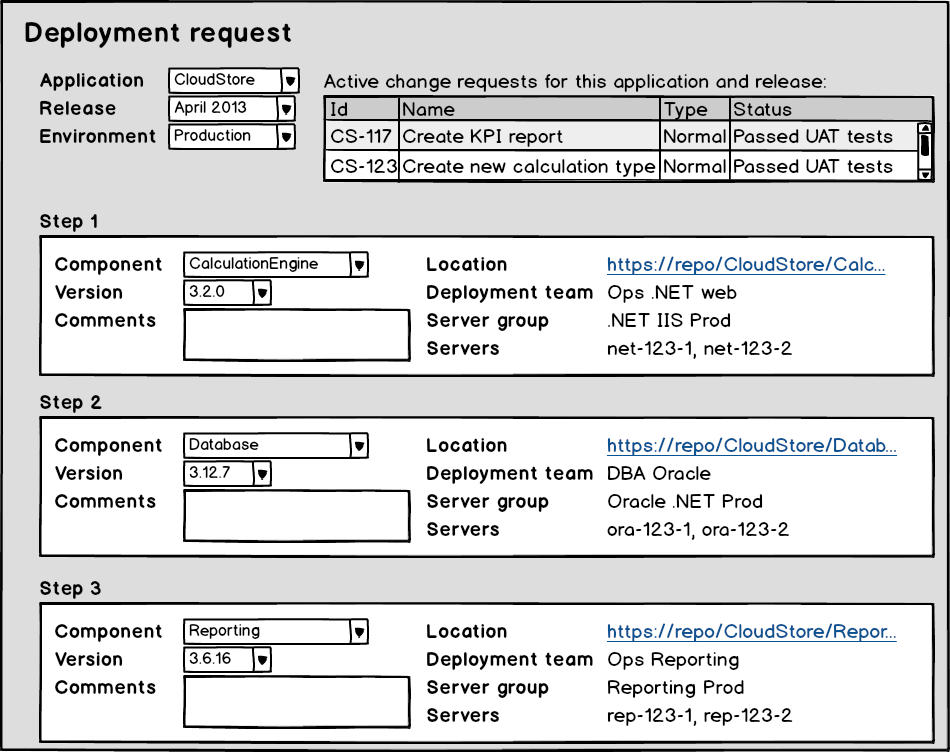
The deployment requests were documented in Word and contained the detailed instructions on how to deploy the relevant software components, config files, etc. The deployment request was limited to one development team, one application and one or more change requests.
During the day of the deployment the release coordinator then coordinated the deployments of the requests with the different ops teams.
This whole flow of documents from the developers through the release coordinator to the ops teams was done through simple mails. As was the feedback from the ops teams: a simple confirmation if all went OK but in case something unexpected occurred the mail thread could quickly grow in size (and recipients) while bumping from one team to the other.
The release coordinator organized pre-deployment and post-deployment meetings with the representatives of the development and ops teams. The former to review the release plan he had assembled, the latter to do no-blame root cause analysis of encountered issues and to improve future releases.
A technically oriented CAB was organized the Monday before the production deployment weekend and included representatives of the development teams, ops teams, infrastructure architects, the change manager and the release coordinator. The purpose of this meeting was to loop through the change requests that were assigned to the coming release and to assess their technical risk before giving them a final GO/NOGO. The business side was typically not represented during this meeting so the business risk assessment done here was limited.
The Operations teams
The operations department consisted of several teams that each were responsible for a specific type of resource: business applications, databases, all types of middleware, servers, networks, firewalls, storage, etc.
Some of these teams were internal, others were part of an external provider. The internal teams were in general easily accessible (not in the least because of their physical presence close to the development teams) and had a get-the-job-done mentality: if a particular deployment instruction didn’t work as expected they would first try to solve it themselves using their own experience and creativity and if that didn’t do it they would contact the developer and ask him to come over to help solve the problem.
The external teams on the other hand worked according to contractually agreed upon SLA’s, their responsibilities were well defined and the communication channels were more formal. As a result there was less personal interaction with the developers. Issues during the deployments – even minor ones – would typically be escalated during which the deployment would be put on hold until a corrective action was requested.
It was not always simple for developers to find out which ops team was responsible for executing a particular deployment instruction. E.g. regular commands had to be executed by team X, while the commands that required root access had to be executed by team Y. Or database scripts were executed by DBA team X in UAT but by DBA team Y in production. On top of that, these decision trees were quite prone to change over time. And just like in the development teams not all members of the ops team had the same profile or experience.
The Test teams
The testers were actually part of the development teams which means that there was no dedicated test team.
Although some of the development teams extensively used unit-testing to test the behaviour of their applications, the integration and acceptance testing was still a very manual activity. There were a couple of reasons for this. To start with, some of the development tools and many of the business applications just didn’t lend themselves easily (at least not out-of-the-box) to setting up automated testing. Secondly, there was limited experience within the company to set up automated testing. Occasionally someone would initiate an attempt at the automated testing of a small piece of software in his corner but without the support of the rest of the community (developers, ops people, management, …) this initiative would die out soon.
Another phenomenon I noticed was the fact that the testers preferred to test on a copy of the production data (not even a subset of the most recent data but a copywith the full history). I’m sure they will need less efforts to spot inconsistencies in a context that closely resembles real life but there are some major disadvantages with this approach as well. First of all disk space (especially in a RAID5 setup) needed by the databases doesn’t come for free. Secondly you have the long waiting time when copying the data from production to test or when taking a backup before a complex database script is executed. And finally and maybe most importantly there is the “needle-in-a-haystack” feeling that comes up whenever the developer has to search the root cause of a discovered issue while digging through thousands or even millions of records.
The OTHER teams
I will not go in detail on the Security, Procurement, PMO, Methodology and Audit teams because they are typically less involved with the delivery of changes to existing applications (the focus of this post) then they are with the setup of new projects and applications.
Side note: So why did we have company-wide releases and why did they happen so infrequently?
The reasons can be found in the decisions that were taken in the other teams:
- Due to the design of the functional architecture (in particular the many third party applications and the central data hub) most of the changes had impacts on multiple applications simultaneously so there was a need for at least some orchestrated release efforts anyway
- Due to the manual nature of the deployments there was a financial motivation to rationalize on the number of weekends that the ops teams had to be on-site
- Due to the manual nature of testing here as well there was a financial (but in this case also a planning-wise) motivation to combine the changes as much as possible into one regression testing effort
- Avoiding the need for application deployments during each weekend freed up the other weekend for doing pure infrastructure-related releases
OK that was it for the explanation of the teams, time for a little recap now:
In the previous sections we have seen that the IT department was characterized by the following aspects:
- The heterogeneity of the application landscape, the development teams and the ops teams:

- The strong focus on the integration of the business applications and the high degree of coupling due to the sharing of the data hub and the ETL/EAI platform:

- The manual nature of configuration management, release management, acceptance testing, server provisioning and environment creation:

- The fact that the IT processes are governed by corporate frameworks (CMMi, ITIL, TOGAF)
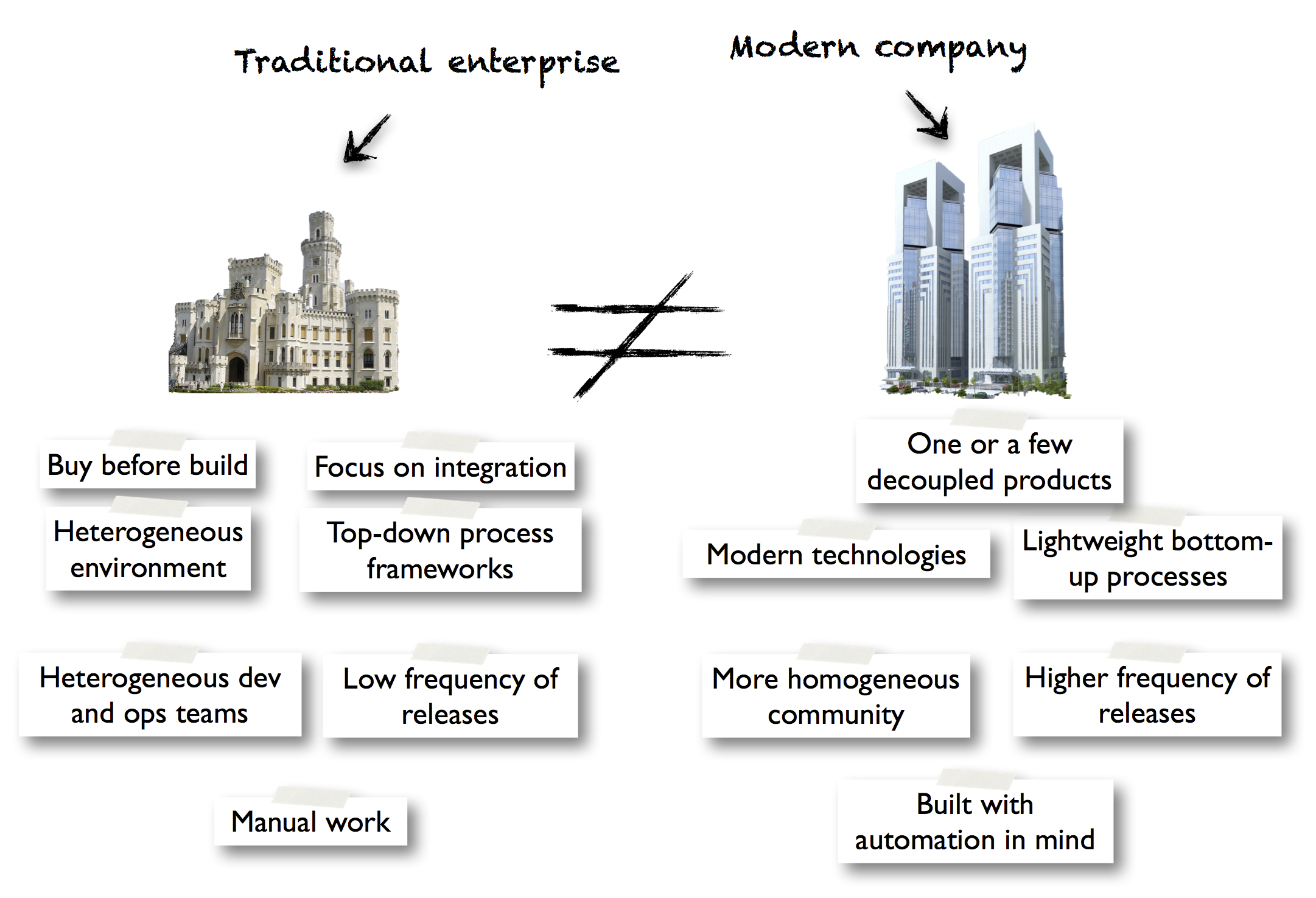
Although I have no real-life experience yet with working in a “modern/web 2.0/startup-type” of company, from what I have read and heard they are more homogeneous in technology as well as in culture, they usually work on one or a few big componentized (but decoupled) products, were built with automation written in their DNA and are guided by lightweight, organically grown IT processes. All in all very different from the type of company I just described. It seems to me that although both types of companies (the traditional and the modern) have in common that they both want to make money by strategically using IT, they differ in the fundamentals on which their IT department is built.
Now that you have a better understanding of the roles and responsibilities that were involved in the world of software delivery let us have a look at the biggest problems that existed.
Problems
 release coordination
release coordination
As already mentioned, the release consists of a set of phases. One of them is the UAT phase and takes between one and two weeks. During this phase the software is deployed and acceptance tested. The time foreseen for the deployment of the software is referred to by the term ‘deployment window’.
It turned out that the deployments consistently started to run outside of this deployment window, thereby putting more and more stress on the downstream plannings.
The reason for this is as following. The development teams and ops teams had been growing more a less linearly over time during the last couple of years, but because the complexity of the release coordination (and in turn the effort needed) depends on the number of connections between these two sides the release management team had to grow exponentially to keep up with the pace. And due to the manual nature of the release coordination work this added complexity and effort translated in exponentially more time needed. I know this explanation is far from scientific but you get the point.
Deployment instructions
One of the long standing problems – and a source of friction and frustration by whomever came in touch with it – were the way in which the deployment instructions were written.
First of all the instructions lacked standardization. Even for the technologies that had build and deployment scripts the instructions were by some people written as the whole command to be run (e.g. “deploy.sh <component name> <version>”), by others in pure descriptive text (e.g. “please deploy version 1.2.3 of component XYZ”) and in some rare cases the deployment script was even replaced by a custom deployment process. Note that this problem had been addressed at some point by requiring the usage of “template” instructions for the core development technologies and consisted of a predefined structure with a field for each parameter of the script.
The instructions for technologies that had no build or deployment scripts also lacked standardization regarding the location of the source files: sometimes they were made available on a shared location (writable to everyone within the company), other times they were shared from the developer’s pc or pre-uploaded to the server. A closely related problem was that the links to these files sometimes referred to non-existent or outdated files.
Many instructions were also too vague or required too much technical knowledge on the technology or the infrastructure for the ops teams to understand them correctly.
Regularly steps were missing from the instructions which caused the application to fail during the restart. It could be a whole component that was not updated to the intended version, or simply a directory that was not created.
And finally there were the minor errors like copy/paste errors, typos, the Word doc that cuts a long command and adds a space, etc. You name it, I probably have witnessed it 😉
We can summarize this problem by saying that the devs and ops teams lack the mutual understanding that is necessary to efficiently communicate with each other, or in other words the ops teams are not able to make the assumptions that are implicitly expected by the dev teams.
No matter what was the source of the bad or wrong deployment instructions, one thing was certain: it would take a lot of efforts and time from everyone involved to get the instructions corrected. Not to mention the frustration, the friction and the bad image it caused to the whole software delivery experience.
What was even more destructive was the fact that after too many troubleshooting efforts and the accompanying corrective actions the exact steps to deploy the application got lost in the dust and a new snowflake server was born.
Configuration management
Here we arrive at the core of the whole ecosystem and also my favorite subject: configuration management. It represents the foundation on which the castle is built so the smallest problem here may have major consequences further on.
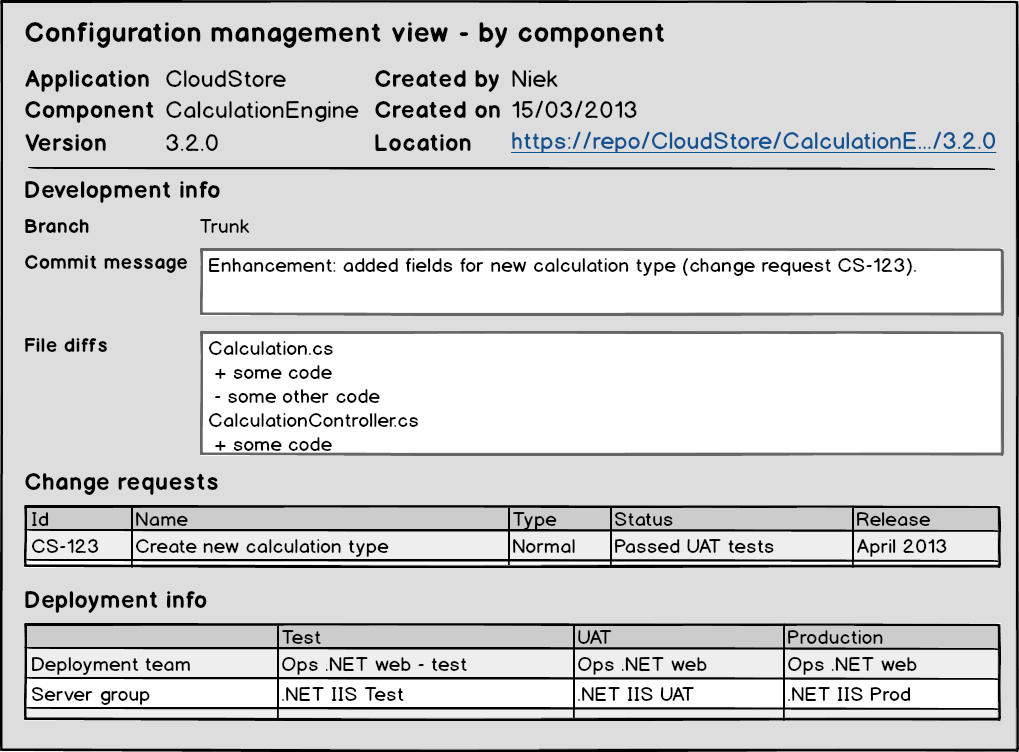
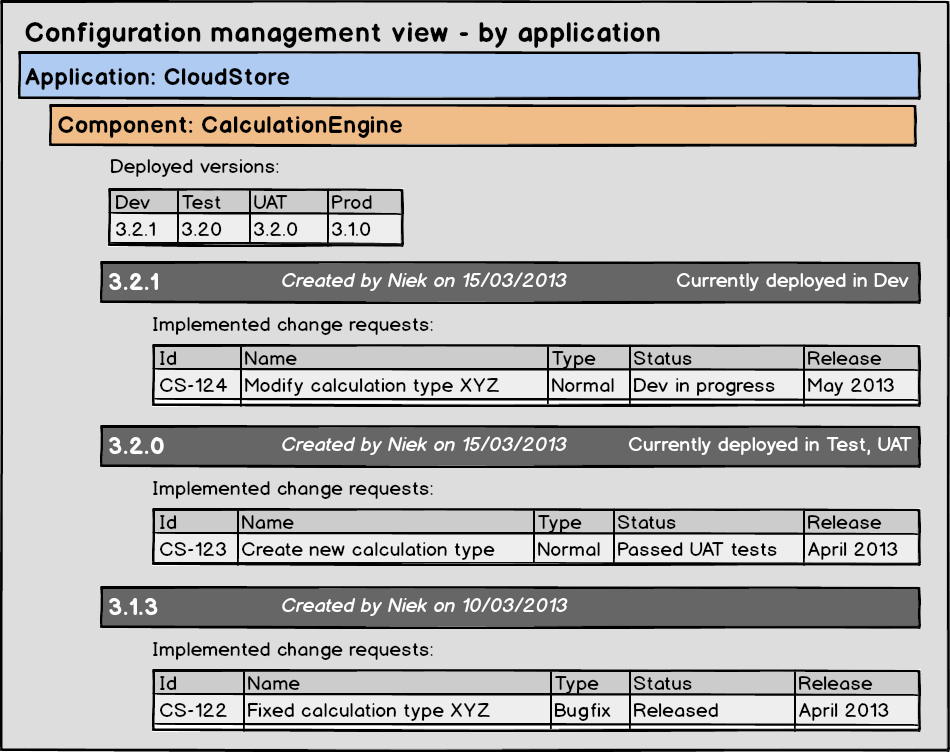
To start with, there was no clear list of all business applications – what is called a service catalog in ITIL – that existed within the IT department and neither was it clear who was the business owner or the technical owner of each application. There was also no clear view on which components an application was exactly made up of.
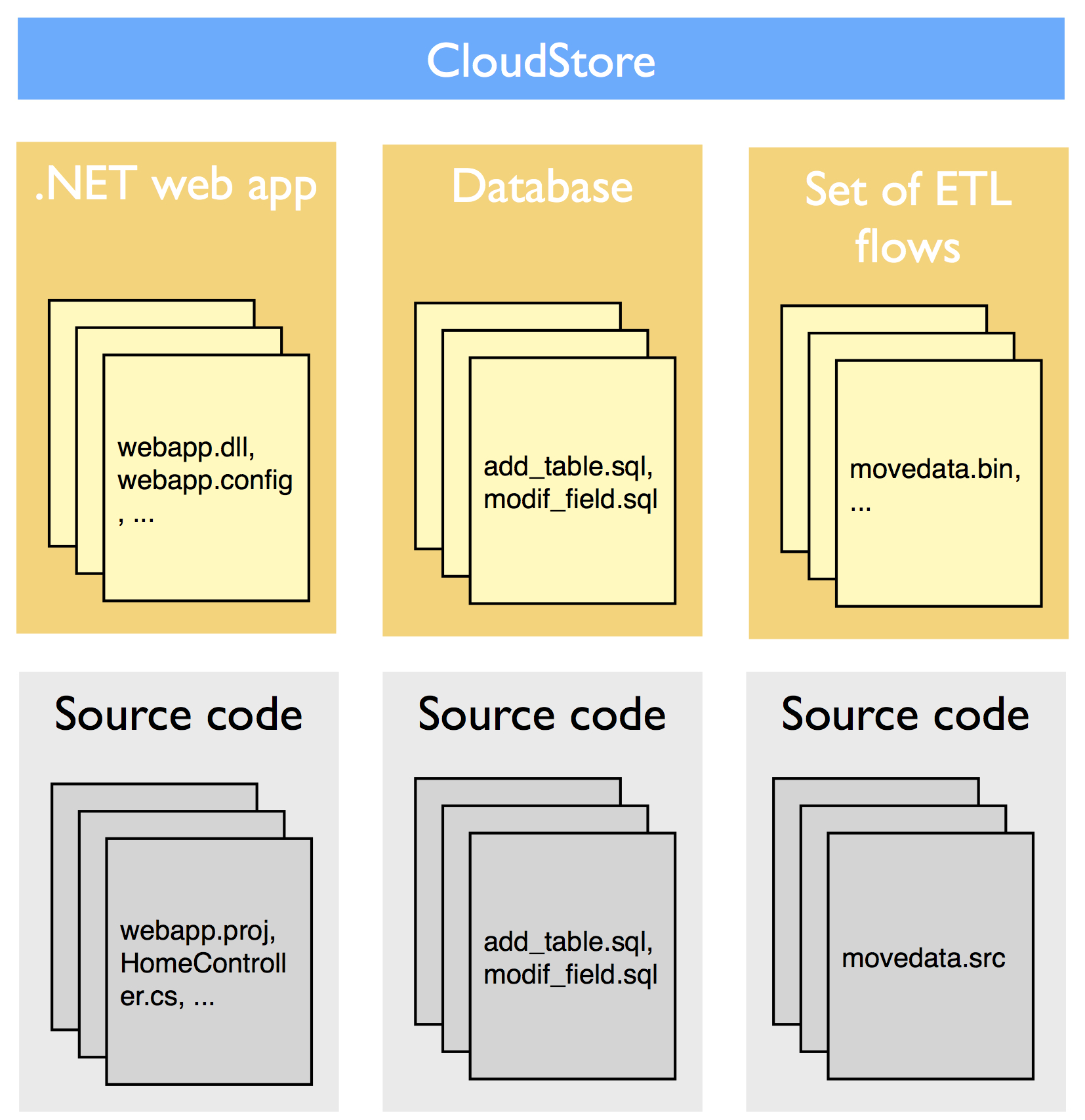
Note that with (business) application I mean the higher-level concept that delivers a business value, while with a (software) component I mean a deployable software package like a web application, a logical database, a set of related ETL flows or BO reports, etc. An application is made up of a set of components.
We already saw that many processes were manual. One of the consequences was that this allowed for too much freedom on the structure of configuration management:
- Different teams were able to work on the same component (this was an issue of code ownership)
- The same deployment request sometimes contained the instructions for components of more than one applications
- Components were sometimes moved from one application to another to avoid creating too much deployment requests
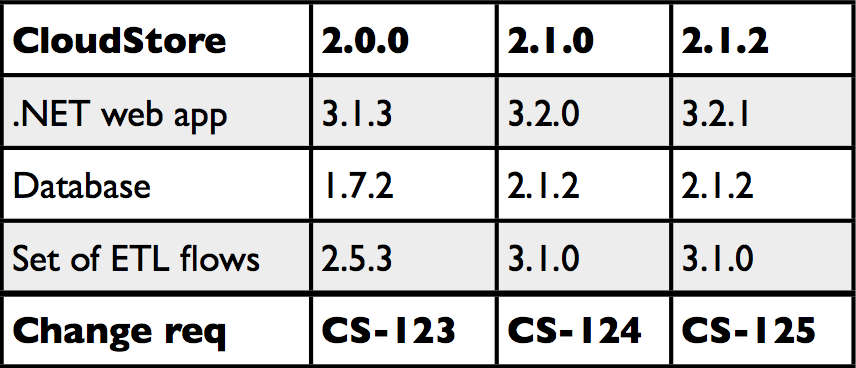
- Component version numbers were sometimes recycled for later versions which made it impossible to unambiguously link a version number with a specific feature set
There were many other issues that were very specific to this particular context but it would lead us too far to explain them here.
All these issues made it very hard or even impossible to keep track of which code base (or version number) of the application was linked to which feature set, which one was deployed in the test environments, which one was signed-off by the testers and which one was allowed to go into production.
Testing/QA
The UAT phase took between one and two weeks during which the software had to be deployed and the changes tested and hopefully signed-off by the testers.
Due to the aforementioned problems the deployments took considerably more time than initially planned for and as such reduced the period during which the tests could be run.
Moreover, testing was a manual process and even with a full testing period the testers workforce was too small to test all edge cases and regressions.
For these two reasons it happened that testers were not able to sign-off the change requests before the deadline. These change requests (and the components that were modified to implement them) then had to be removed from the release which resulted on its turn in the need for a last-minute impact analysis to identify and remove all related change requests. The effect of this analysis was worsened by the many integrations (i.e. there was a high degree of coupling between the changes and components), the huge size of the releases (in the end every component becomes directly or indirectly dependent on each other component), the lack of configuration management and arguably the most dangerous of all: the lack of time to retest the changes that were kept in the release.
Hacking
Due to the pressure of the business to deliver new features and to the low release frequency there was a tendency by developers to try to find ways to bypass the restrictions that were imposed by the release management process.
One of these “hacks” was to sneak new features in the release just before the deployment to production by overwriting the source files with an updated version while keeping the same version number as the tested and signed-off one.
Due to a lack of branching in some technologies it also happened (especially as part of urgent bug fixes) that individual files were sent over to the ops teams instead of the whole deployable unit.
All of these non-standard activities contributed to the difficulty to do proper configuration management.
Conclusion
OK that’s about all of the high priority problems that existed in the company. Now we are armed with the proper knowledge to start looking for solutions.
Congratulations if you made it till here! It means that you are very passionate – like me – about the subject. It was initially not my intention to create such a long and heavy post but I felt it was the only way to give you a real sense of the complexity of the subject in a real environment.
In my next post I will explain how we were able to bring configuration management under control and how we implemented a release management tool on top of it that used all the information that was already available in the other systems to facilitate the administrative and recurrent work of the developers, release coordinator and ops teams so that they could concentrate on the more interesting and challenging problems.
I will also take a closer look at the possible solutions that exist to tackle the remaining problems in order to gradually evolve to our beloved “fast changes & reliable environment” goal.
Previous posts in the series:
Next posts in the series:

 In this post I will take it one step further and ask the question why they are so different in the first place. And, if this difference is only “cultural” rather than “genetic”, whether it is possible to transform the traditional enterprises to modern ones, instead of awkwardly trying to squeeze these successful patterns (I’m talking about agile, DevOps and CD here) in to them.
In this post I will take it one step further and ask the question why they are so different in the first place. And, if this difference is only “cultural” rather than “genetic”, whether it is possible to transform the traditional enterprises to modern ones, instead of awkwardly trying to squeeze these successful patterns (I’m talking about agile, DevOps and CD here) in to them.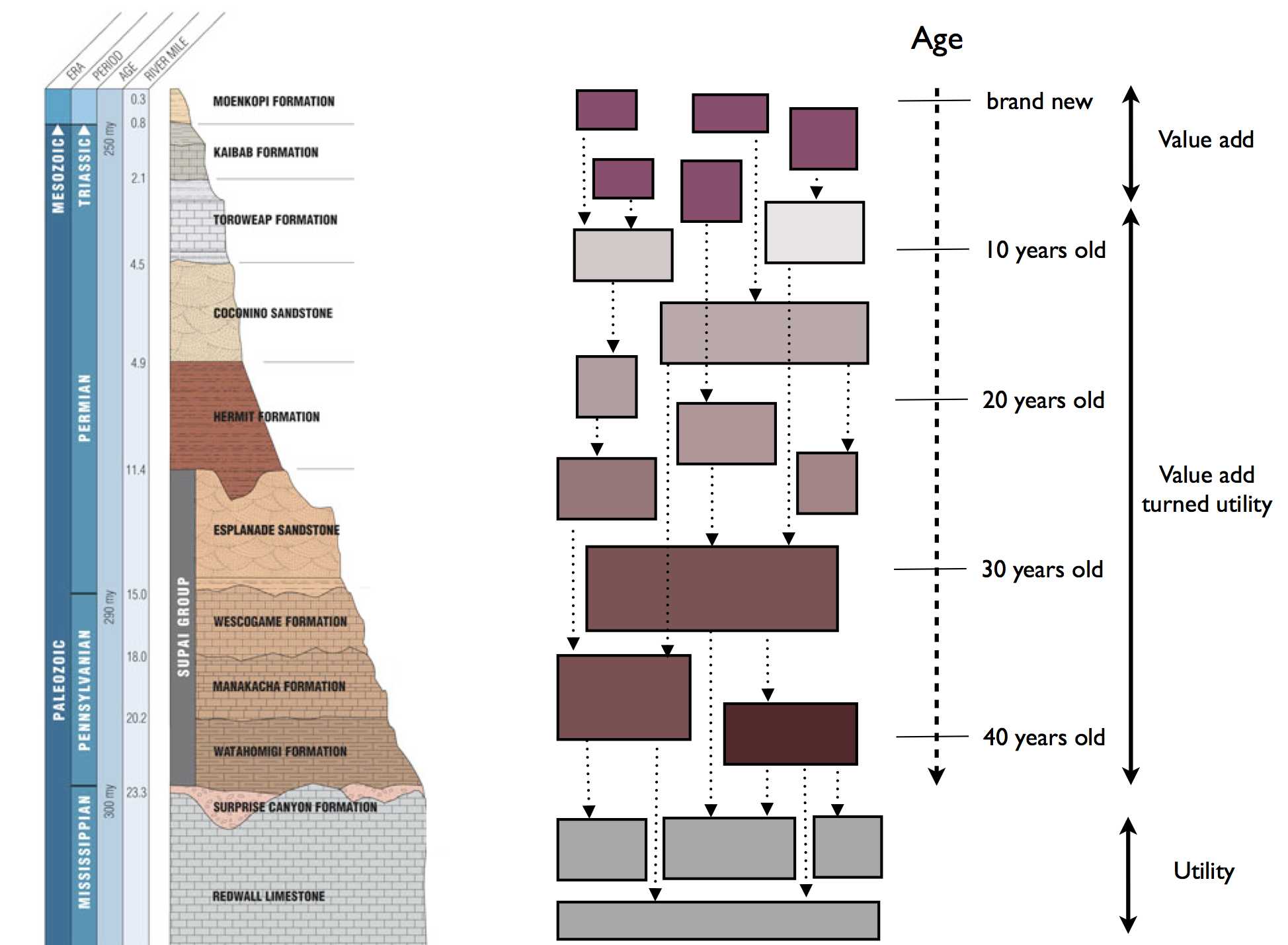 Finally, the articles make the implicit assumption that value adding projects are all about trying to find ways to innovate, in an attempt to keep an edge over the competition. I believe that there a many markets where this is not the case. Markets with high entrance barriers or that favor monopolistic behavior are examples where added value remains stable for longer periods. I argue that these “mature” value adding projects could as well be treated as “value add turned utility” projects. Because they are so similar it would be hard anyway to draw a line between them.
Finally, the articles make the implicit assumption that value adding projects are all about trying to find ways to innovate, in an attempt to keep an edge over the competition. I believe that there a many markets where this is not the case. Markets with high entrance barriers or that favor monopolistic behavior are examples where added value remains stable for longer periods. I argue that these “mature” value adding projects could as well be treated as “value add turned utility” projects. Because they are so similar it would be hard anyway to draw a line between them.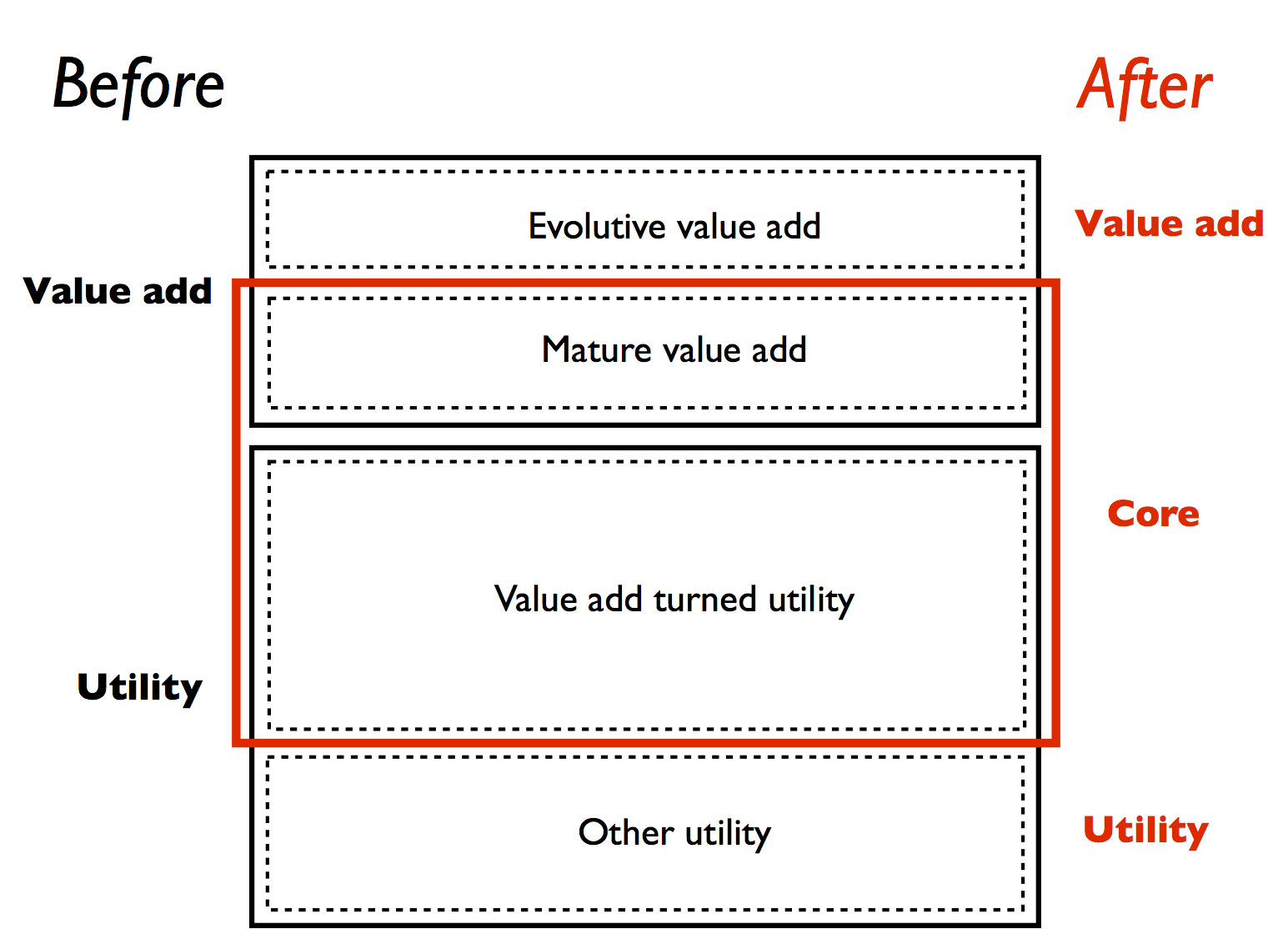 As with the other two categories, this core category also has a very specific nature and must therefore be treated in its own way. Compared to value adding projects the core projects have more dependencies and should therefore focus more on risk-aversion. As they are more mature they have less need for creative ad hoc thinking and quick time-to-market. They are less likely to deliver high returns so cost effectiveness should also get a bigger focus. For these reasons they may be a better fit for process-centric approaches like ITIL and CMMi (one of the two M’s stands for … maturity) than the value added projects.
As with the other two categories, this core category also has a very specific nature and must therefore be treated in its own way. Compared to value adding projects the core projects have more dependencies and should therefore focus more on risk-aversion. As they are more mature they have less need for creative ad hoc thinking and quick time-to-market. They are less likely to deliver high returns so cost effectiveness should also get a bigger focus. For these reasons they may be a better fit for process-centric approaches like ITIL and CMMi (one of the two M’s stands for … maturity) than the value added projects.